





Do czego służy XPath?
XPath (XML Path Language) jest językiem ułatwiającym poruszanie się po elementach DOM, poprzez generowanie kontentu w XML, który jest rozszerzalnym językiem znaczników (eXtensible Markup Language).
XPath używany jest do tworzenia ścieżek wyrażeń opartych na węzłach dokumentu DOM. Stworzona ścieżka przypomina tą, którą często widzimy tworząc jakiś plik.
Wielką zaletą XPath jest szeroki zbiór języków wspieranych, do których należą m.in. Java, JavaScript czy Python.
Wiadomości wstępne
Drzewo obiektowego model dokumentu (DOM) pozwala na manipulowanie HTML-em na różne sposoby. W jego skład wchodzą znaczniki i atrybuty języka HTML, np. <html>, <p id="text">, <h1> czy <input id="display_name" class="input_message" type="text" name="display_name">. Dokument HTML ma strukturę hierarchiczną, zatem elementy strony posiadają swoje dzieci i rodziców. Rodzicami są elementy nadrzędne, zaś dziećmi – podrzędne. Dzięki takiemu podejściu hierarchia drzewa DOM jest porównywana do drzewa genealogicznego. Znaczniki HTML są właściwie węzłami DOM, wykorzystywane są do tworzenia wartościowych ścieżek XPath. Zanim jednak do tego przejdziemy, przypomnijmy sobie troszkę teorii...
Czym są lokatory?
Każdy element HTML jest reprezentacją webelementów, należących do Interfesju WebElement (Selenium), na podstawie których tworzy się lokatory. Używany przez nas driver identyfikuje webelementy, a dzięki Selenium mamy możliwość rozpoznawania elementów na stronie. Do metod znajdowania lokatorów zaliczamy:
- id,
- name,
- XPath,
- LinkText,
- PartialLinkText,
- tag name,
- class name,
- CSS Selector.
Ale gdzie ich szukać? I w jaki sposób je znaleźć?
Otóż nie trzeba szukać niczego skomplikowanego, gdyż wszystko znajdziemy na stronie internetowej. Wystarczy jedynie kliknąć prawym klawiszem myszy na odpowiedni element i wybrać opcję "Zbadaj element", po czym przeglądarka przenosi nas w strukturze strony do konkretnego elementu.
Przykład 1.
Wszystkie przykłady zostały wykonane na podstawie strony przygotowanej przez twórców frameworku Selenium: http://automationpractice.com/index.php.
Odszukajmy w strukturze HTML przycisk wyszukiwania, w tym celu kliknijmy w ten element prawym przyciskiem myszy i wybierzmy opcję "Zbadaj"
Następnie zostajemy przeniesieni do widoku developerskiego, tzw. "Developer tools". Na niebiesko został zaznaczony szukany przez nas element.
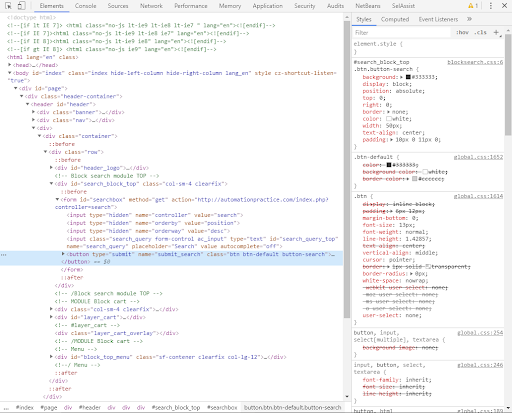
Będąc już w narzędziach dla programisty, w łatwy sposób możemy badać kolejne elementy, wystarczy tylko kliknąć w lewy górny róg i wybrać kolejny webelement, który chcemy znaleźć.
Zasady dobrego lokatora
Ale skąd wiadomo, na które informacje warto zwrócić uwagę przy tworzeniu lokatora?
Lokator powinien być:
- unikalny, czyli powinien wskazywać na konkretny element,
- krótki – dotyczy to głównie CSS i XPath – każdy kolejny człon w wyrażeniu to potencjalny czynnik, który może zmienić deweloper, stąd bezpieczniej jest tworzyć krótkie selektory, które prawdopodobnie nie ulegną zmianie,
- prosty - jak najmniej skomplikowany i jak najbardziej zrozumiały dla nas i reszty zespołu,
- opisowy i jednoznaczny – CSS Selector i XPath – nie mamy problemu
z zidentyfikowaniem webelementu na stronie.
Najczęściej polecane są lokatory powstałe z:
- id,
- name,
- Class name,
- Xpath/CSS.
Tak więc rozpoczynamy szukanie lokatora - od zweryfikowania czy posiada on atrybut id. Gdy niestety element go nie posiada, sprawdzamy atrybut name. W momencie gdy nasz element nie zawiera tych elementów, swoją uwagę kierujemy w stronę Class name, ale nic na siłę. Jeśli webelement ma unikalną klasę to super, cieszymy się i używamy. Jednak, gdy klasa odnosi się do przynajmniej dwóch elementów, to mamy do wyboru dwie opcje, albo stworzyć CSS Selector albo XPath.
Dlaczego nie rekomenduje się użycia pozostałych metod?
Ponieważ LinkText lub PartialLinkText mogą zostać zmienione w każdym momencie wraz z zawartością strony oraz nie wspierają testowania różnych wersji językowych aplikacji webowej.
Skąd wiadomo kiedy użyć XPath a kiedy CSS?
Zależność strategii wyboru lokatora oparta jest na kontekście tego co chcemy zrobić. Najczęściej XPath stosuje się, gdy mamy trudny webelement o długiej ścieżce oraz, gdy wspieramy starsze przeglądarki. CSS jest używany w momencie, gdy wspieramy nowoczesne przeglądarki i nie mamy potrzeby składać skomplikowanych selektorów.
Ważną różnicą pomiędzy obydwoma sposobami jest fakt, iż wyrażenia XPath umożliwiają wyszukanie elementów w strukturze naszej strony wstecz lub w przód, zaś CSS pozwala na operowanie tylko do przodu.
Tworzenie Xpath
Zaznaczanie względne i bezwzględne elementów
XPath można podzielić według stworzonej ścieżki na podstawie lokatora na:
- XPath bezwzględny, to bezpośrednia ścieżka do poszukiwanego przez nas elementu, zapisana "na sztywno". Takie ścieżki są w dużym stopniu podatne na zmiany w strukturze HTML.
- XPath względny posiada tylko elementy potrzebne do zidentyfikowania szukanego elementu, są to tzw. koordynaty. Z reguły występuje jako modyfikacja schematu:
//nazwa_tagu[@atrybt=’wartość’].
Przykład 2.
Porównajmy do siebie obie grupy lokatorów XPath. Przedstawione ścieżki skierowane są do tego samego elementu – pola służącego do wpisania e-maila podczas rejestracji subskrypcji newslettera.
- Bezwzględny.
/html/body/div/div/footer/div/div/div/form/div/input[@id='newsletter-input'] - Względny.
//input[@id='newsletter-input']
Widać zdecydowaną różnicę w budowie lokatorów. Pierwszy z nich przestanie być aktualny po minimalnej zmianie hierarchii struktury strony. Jest niezrozumiały i trudny w wytłumaczeniu. Drugi zaś jest prosty, krótki i konkretny. Zawiera najważniejsze informacje o szukanym elemencie, tylko te, które są konieczne. Dzięki temu, gdy deweloperzy zmienią strukturę strony, a ścieżka zostanie nadal aktualna. Ponadto jest czytelna i od razu widać, o który webelement nam chodzi.
Elementy składni XPath
Najważniejsze elementy składni języka XPath znajdują się w tabeli poniżej.
| Element składni XPath | Opis elementu |
|---|---|
| / | Wyszukanie węzła od najwyższego poziomu drzewa DOM, ścieżka bezwzględna |
| // | Zaznaczenie elementu bez względu na jego lokalizację, ścieżka względna |
| . | Określenie obecnego węzła |
| .. | Znaczenie węzła nadrzędnego |
| @ | Wskazanie atrybutu |
| * | Określenie wszystkich elementów, które możemy znaleźć |
Zapytasz: "I tylko tyle muszę wiedzieć?" Tak! Na podstawie wymienionych wyrażeń można stworzyć większość lokatorów opartych na XPath, ale trzeba wiedzieć, że możliwości tego języka na tym się nie kończą. Otóż to są jedynie podstawy, chętnych zapraszam do zapoznania się ze serią artykułów w ramach W3C.
Do niektórych ciekawszych możliwości XPath jeszcze wrócę, ale najpierw omówmy przykład, aby zdobytą wiedzę wykorzystać w praktyce.
Wybór elementu o tym samym tagu
Przykład 3.
Znajdźmy XPath dla elementu "Sign in". Zbadajmy, gdzie znajduje się w strukturze dokumentu HTML. Prawym przyciskiem myszy kliknijmy w szukany element, wybierzmy opcję "Zbadaj". Na niebiesko został zaznaczony znaleziony webelement.
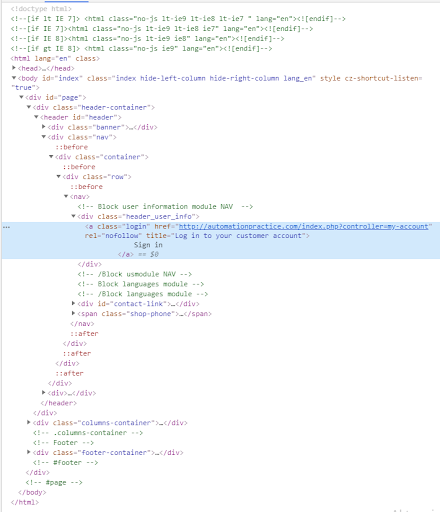
Wybrany przykład posiada jedynie klasę "login", która jest wykorzystana na razie tylko raz. Przeglądarka Chrome umożliwia automatyczne przygotowanie XPath, więc w tym celu kliknijmy prawym przyciskiem w zaznaczony element i wybierzmy opcję "Copy". Pojawiają się sposoby na kopiowanie ścieżki do wskazanego elementu. Użyjmy opcji "Copy full XPath".
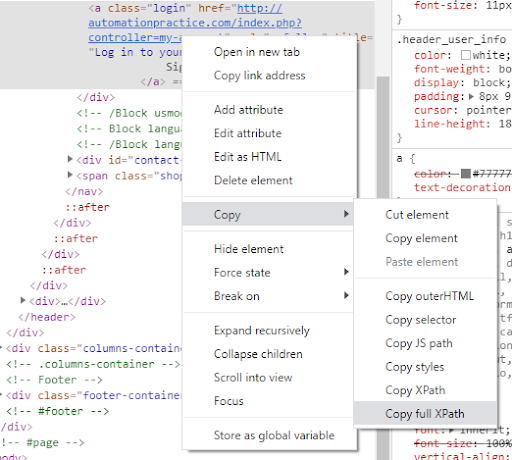
W rezultacie otrzymujemy:
/html/body/div/div[1]/header/div[2]/div/div/nav/div[1]/a
Widzimy jednak, że ten lokator jest zbyt długi i w momencie, gdy deweloper zmieni coś w strukturze strony – przestanie działać. A co będzie gdy wybierzemy opcję "Copy XPath"?
//*[@id="header"]/div[2]/div/div/nav/div[1]/a
Ten lokator też nie wygląda zbyt dobrze. Spróbujmy zrobić własny. Więc od czego zacząć?
Spójrzmy jeszcze raz nasz element.
<a class="login” href="http://automationpractice.com/index.php?controller=my-account" rel="nofollow" title="Log in to your customer account">Sign in</a>
Co możemy wykorzystać do tworzenia lokatora?
Mamy znacznik <a>, klasę class=’login’ oraz tekst. Z tekstu zrezygnujmy, bo przecież może ulec zmianie.
Zacznijmy od stworzenia ścieżki relatywnej, wykorzystajmy do tego //, jako kolejny element użyjmy znacznika hiperłącza z nazwą klasy.
//a[@class='login']
Lokator wygląda dużo lepiej. Jest czytelny i krótki. Gdy zostaną wprowadzone zmiany, jest dużo większe prawdopodobieństwo, że nie ulegnie zmianie. Sprawdźmy teraz, czy odpowiednio stworzyliśmy ścieżkę. W tym celu w narzędziach deweloperskich kliknijmy w jakiekolwiek miejsce w kodzie HTML. Dzięki temu po użyciu kombinacji klawiszy "Ctr+F" naszym oczom ukaże się nowe okno wyszukiwania.
Sprawdźmy więc, czy nasz lokator spełnia swoją funkcję.
Od razu po wpisaniu lokatora odnajduje nasz element w strukturze dokumentu HTML. A co jeśli użyta przez nas klasa zostanie wykorzystana ponownie?
Możemy dodać numer elementu, tak jak numeruje się elementy listy. Gdy chcemy znaleźć określony element o tagu li, który znajduje się w drzewie DOM na 5 miejscu, można użyć, np. //li[5]. Sprawdźmy, czy tak przygotowany element zostanie znaleziony.
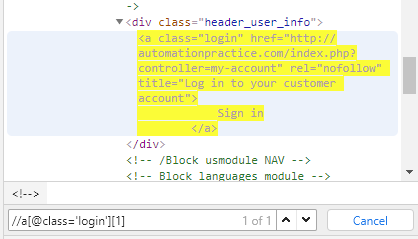
Jak najbardziej! Należy jednak pamiętać, że numer porządkowy rozpoczynamy od 1. Dzięki takiemu zastosowaniu otrzymujemy ostatnio dodany element. Ułatwia to sortowanie, zwiększa efektywność i stabilność strony.
Co jeszcze może się przydać?
Contains()
A co jeśli znacznik posiada więcej niż jedną klasę? Na ratunek przychodzi nam funkcja Contains(), która daje nam możliwość znalezienia elementu, porównując częściową zawartość jego atrybutu. Ma ona jednak inną składnię otóż //nazwa_znacznika[contains(@nazwa_atrybutu, ‘fragment_klasy’)].
Przykład 4.
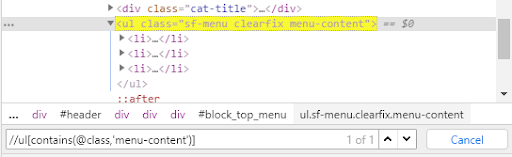
Na naszej testowej stronie mamy listę, prezentującą się w strukturze DOM jako
<ul class="sf-menu clearfix menu-content">
Aby utworzyć do niej lokatora z wykorzystaniem Contains(), wystarczy zapisać
//ul[contains(@class,'menu-content')]
Sprawdzamy, czy nowo utworzony lokator został znaleziony. Ponownie wklejamy ścieżkę do wyszukiwarki i otrzymujemy poniższy wynik.
Warunki w XPath
Do tworzenia lokatorów przy pomocy XPath możemy użyć także warunków i oraz lub. Używając "AND", należy się liczyć z tym, że wszystkie warunki muszą zostać spełnione. Jeśli chodzi o "OR", to przynajmniej jeden warunek musi być prawdziwy.
Przykład 5.
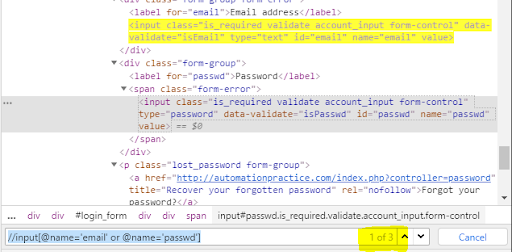
Przejdźmy do zakładki logowania poprzez kliknięcie w "Sign in". Stwórzmy warunek oparty na adresie e-mail i haśle. Pełne ścieżki elementów przedstawione są poniżej.
E-mail - pełny XPath:
/html/body/div/div[2]/div/div[3]/div/div/div[2]/form/div/div[1]/input
Element e-mail w HTML:
<input class="is_required validate account_input form-control" data-validate="isEmail" type="text" id="email" name="email" value="">
Hasło – pełny XPath:
/html/body/div/div[2]/div/div[3]/div/div/div[2]/form/div/div[2]/span/input
Element hasło w HTML:
<input class="is_required validate account_input form-control" type="password" data-validate="isPasswd" id="passwd" name="passwd" value="">
Połączmy teraz oba webelementy jednym warunkiem or, otrzymując:
//input[@name='email' or @name='passwd']
Dzięki temu uzyskamy zaznaczony jeden element, mimo że wskazaliśmy dwa poprawne. Natomiast w samym wyniku otrzymujemy więcej webelementów spełniających warunek.
W przypadku warunku and połączmy atrybut name należącym do hasła wraz z jego typem. W wyniku otrzymujemy tylko wyniki, których to lokator spełnia wskazane warunki.
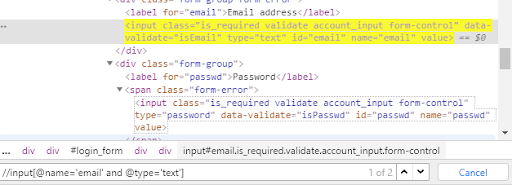
Jak widzimy, znaleziono spełniające warunek elementy. Wyszukiwarka odnalazła dwa takie elementy w kodzie HTML, więc sprawdzany warunek należy zmodyfikować tak by wskazywał na jeden webelement.
Należy pamiętać, aby każdy webelement został rozpatrzony indywidualnie podczas wyboru lokatora. Ważne jest także wsparcie webdriverów dla XPath. Niestety nie jest on wspierany do IE9 włącznie. Selenium w swoich możliwościach stara się to nadrobić, jednak z większymi brakami. Pozostałe webdrivery wspierają XPath, zachęcam więc do przetestowania ich. Warto pamiętać, że tworzenie lokatora na podstawie XPath jest ostatecznością. Wcześniej należy sprawdzić, czy nie ma możliwości odwołania się do elementu poprzez id, class, name lub CSS Selector.











